| 7.6.0 |
S3 Bucket Entry
|
| 7.6.1 |
More Configuration
|
| 7.6.2 |
S3 Harvesting
|
| 7.6.3 |
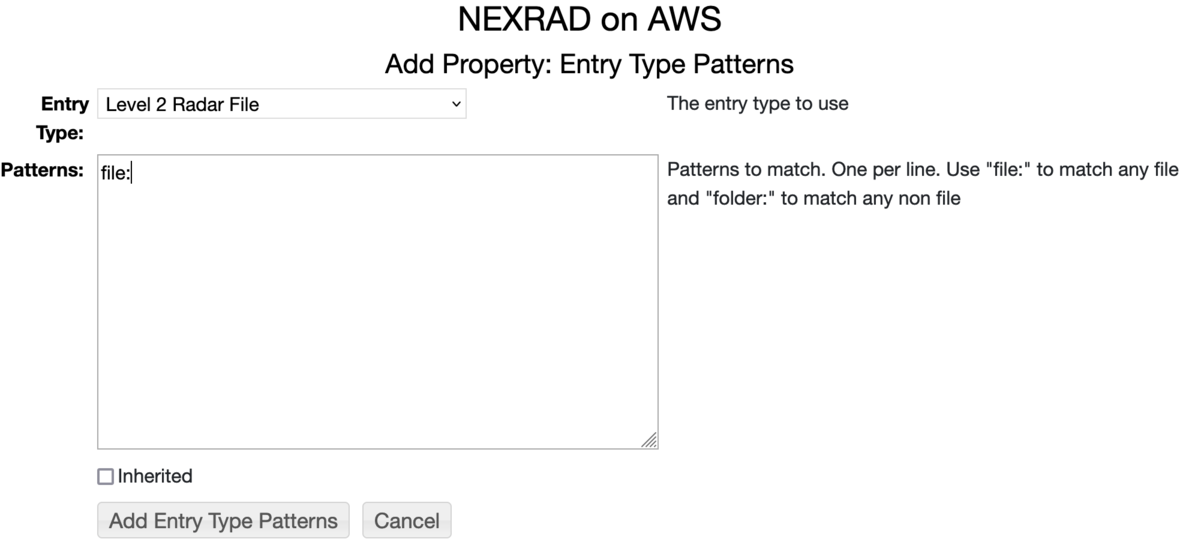
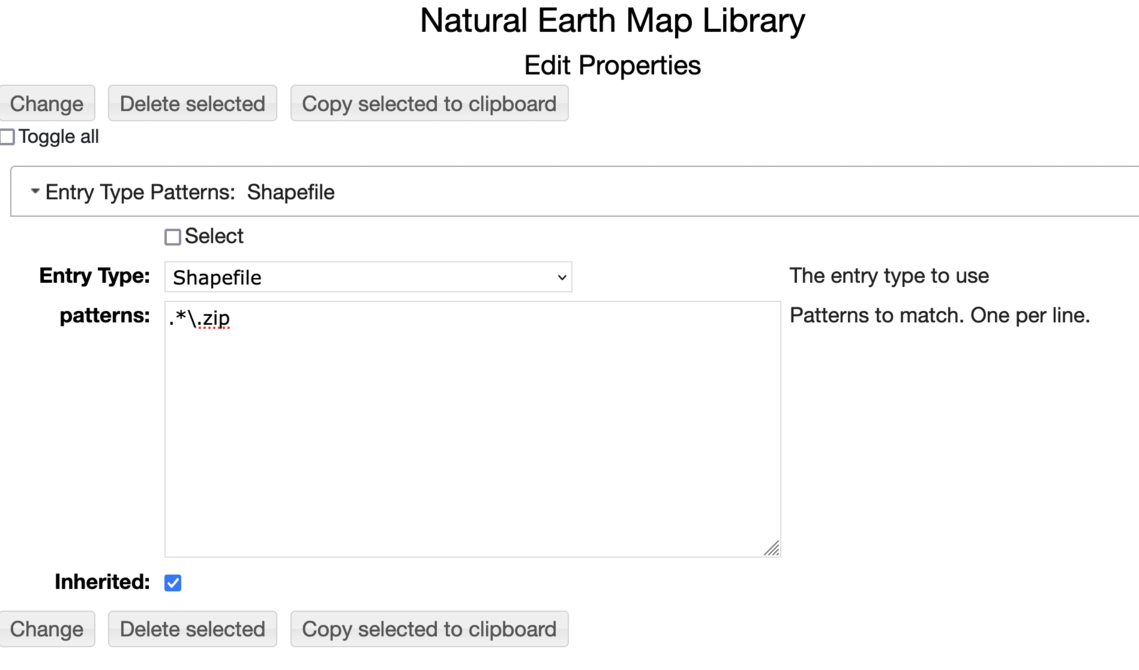
Specifying Entry Types
|
| 7.6.4 |
S3 Tools
|
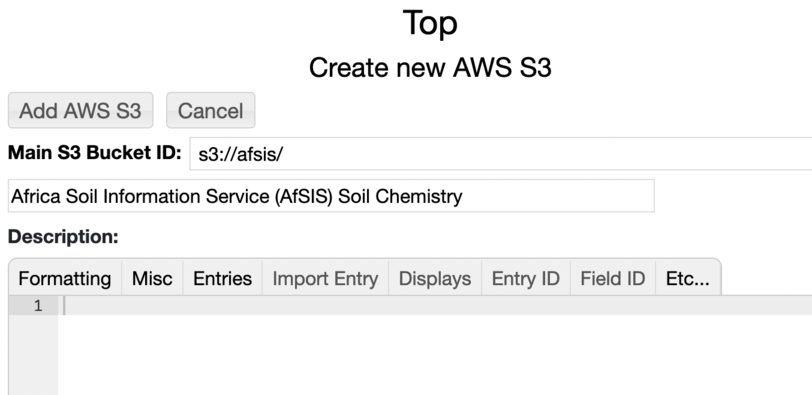
To create a new S3 entry go to the File->Pick a Type menu and select "AWS S3". In the create form entry the S3 URL, a name and an optional description:
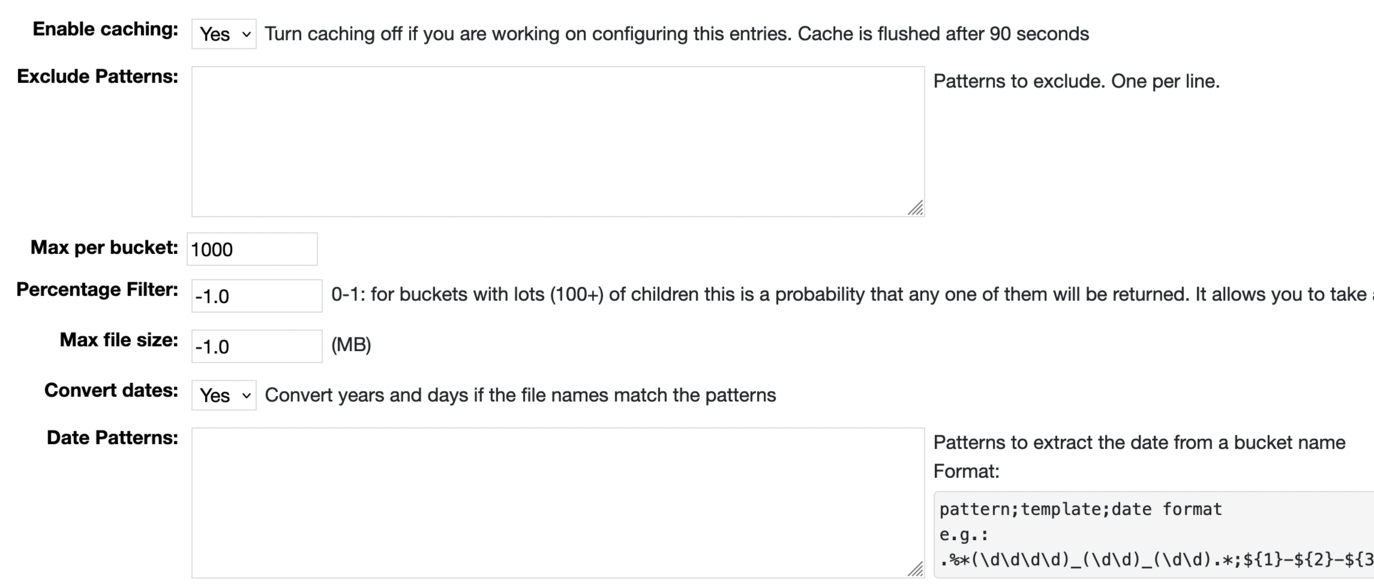
After adding the entry you can edit it to configure how the S3 buckets are displayed.pattern;template;date formatand is used to match against a folder or file name. The pattern needs to contain "(...)" groups. If it matches then the matching groups are extracted and the template (the 2nd part of the 3-tuple) is used to create a date string. This date string is then parsed by the date format.
key1=value1 key2=value2 ...If it is a .txt file then the first line is the key that is matched against the S3 folder names and the rest of the file is a wiki display template:
key_or_pattern wiki text ...
For the NEXRAD example we will upload a nexrad.csv file. This has the following structure:
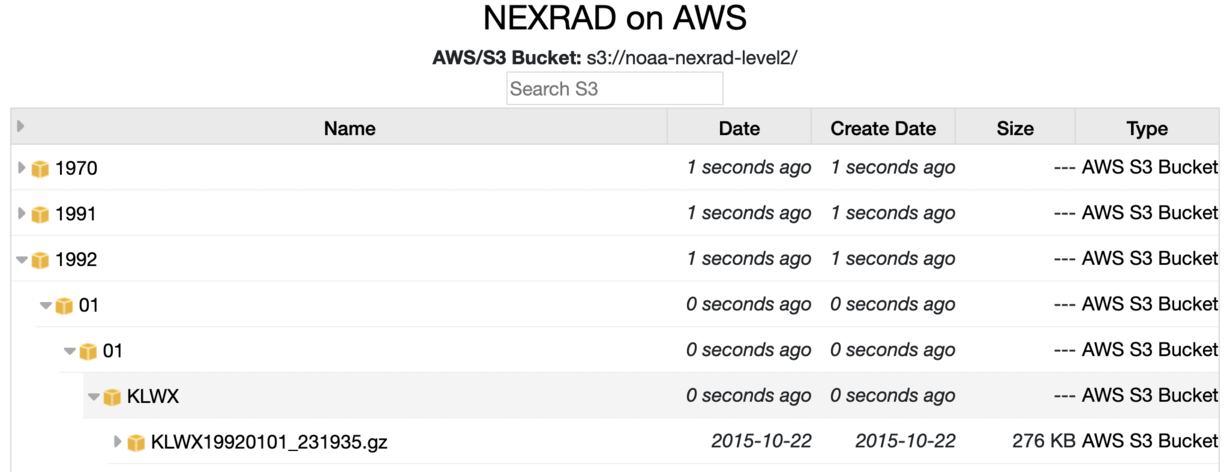
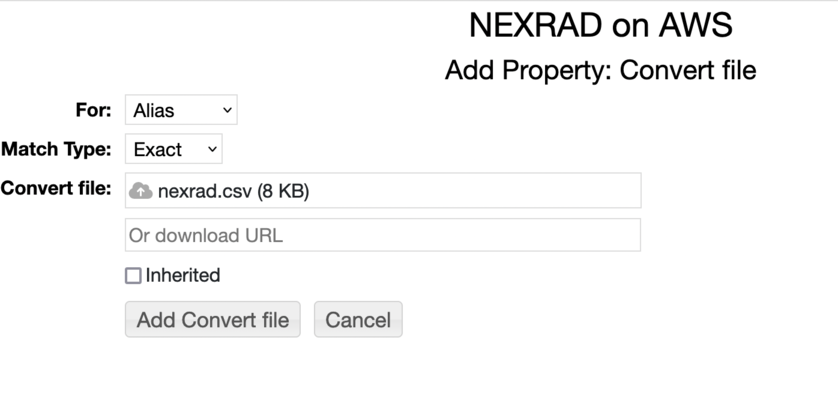
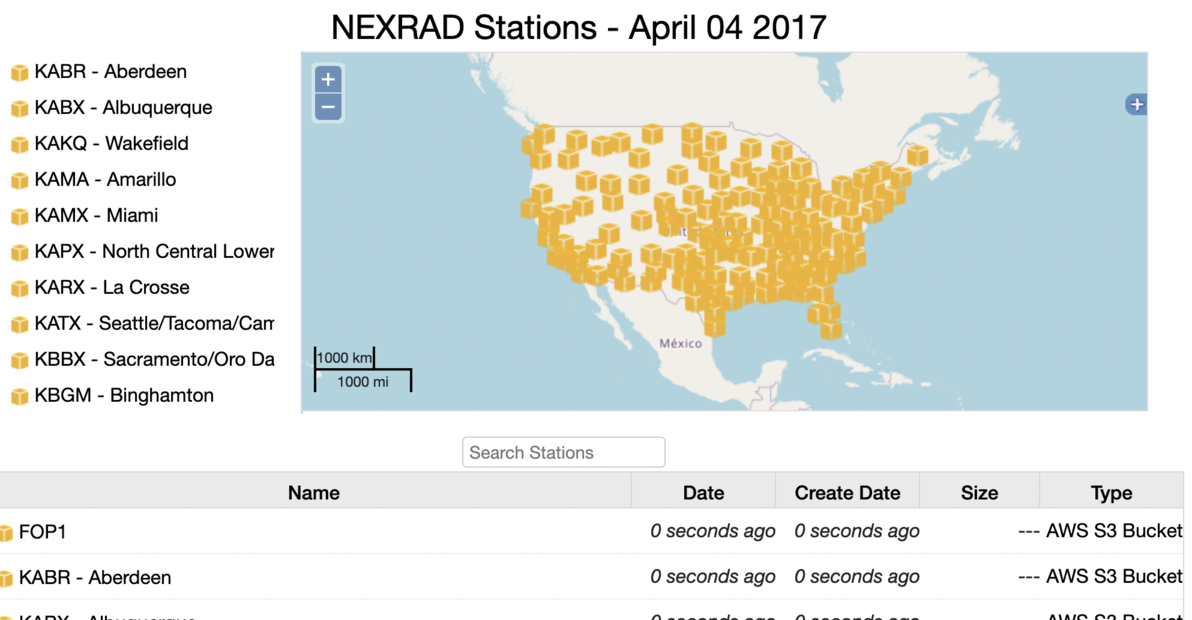
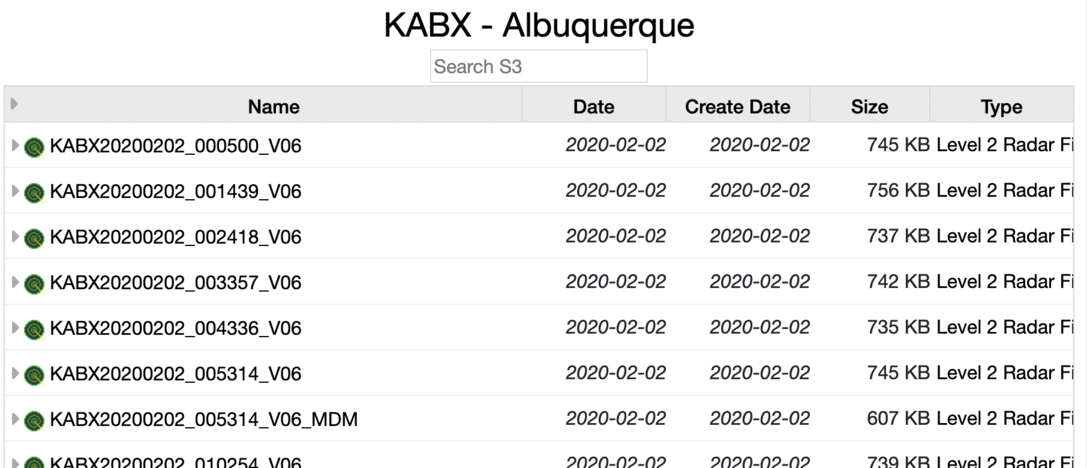
id,fullname,lat,lon KAPD,KAPD - Fairbanks/Pedro Dome,65.035,-147.50167 KAEC,KAEC - Fairbanks/Nome,64.51139,-165.295 KACG,KACG - Juneau/Sitka,56.85278,-135.52917 KAIH,KAIH - Anchorage/Middleton Island,59.46139,-146.30306 ...The first column is the station ID and this is used to match up (either exact or pattern) with the S3 folders. Upload the nexrad.csv file and select Alias and Exact: Now, the station folders have the full name. Next, upload the same file and select "Location". This adds the spatial metadata to the station folders.
Note: we have combined the aliases with the locations. The aliases file could have been a properties file: nexrad_aliases.properties file.
Next, we want to specify the wiki template to be used for the folder that contains the stations, i.e., the year/month/day folder. Here we will upload this nexrad_templates.txt file. It has the format:
^\d\d/\d\d$The first line is a pattern that matches NN/NN, i.e., the month/day folder names. The remainder of the file is the wiki text to be used for the folders that match the pattern. Upload this file, select "Template" and for match type select "Pattern". Now, for the day folder we should have:+section title="NEXRAD Stations - { {name entry=parent} } { {name} } { {name entry=grandparent} }" +inset left=20px right=20px { {map listentries=true hideIfNoLocations=true} } ...
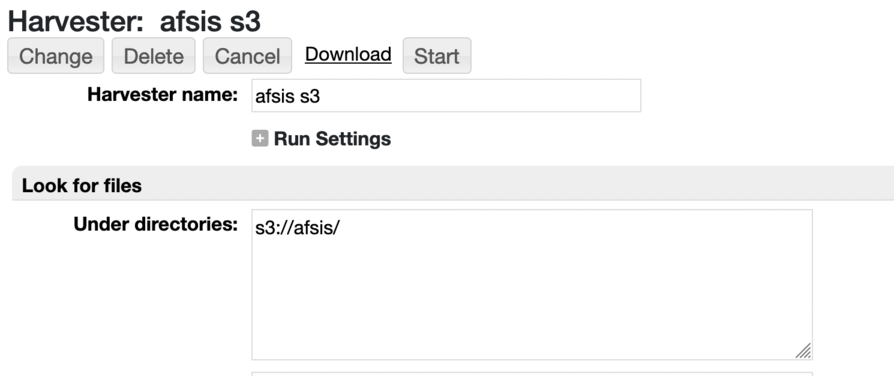
sh s3.sh -help Usage: S3File <-key KEY_SPEC (Key spec is either a accesskey:secretkey or an env variable set to accesskey:secretkey)> <-download download the files> <-nomakedirs don't make a tree when downloading files> <-overwrite overwrite the files when downloading> <-sizelimit size mb (don't download files larger than limit (mb)> <-percent 0-1 (for buckets with many (>100) siblings apply this as percent probablity that the bucket will be downloaded)> <-recursive recurse down the tree when listing> <-search search_term> <-self print out the details about the bucket> ... one or more bucketsAnother utility is provided in the RAMADDA repository runtime at the /aws/s3/list entry point. This provides an interface to the above tool to do a recursive listing of a bucket store. Check it out on https://ramadda.org/repository/aws/s3/list. Try this out with an example:
s3://first-street-climate-risk-statistics-for-noncommercial-use/