RAMADDA has a facility for site administrators to define a monitor for new entries.
A monitor consists of a set of search criteria and an action.
When a new entry is added into the repository all of the monitors are
checked. If a monitor's search criteria matches the new entry then the action is
performed.
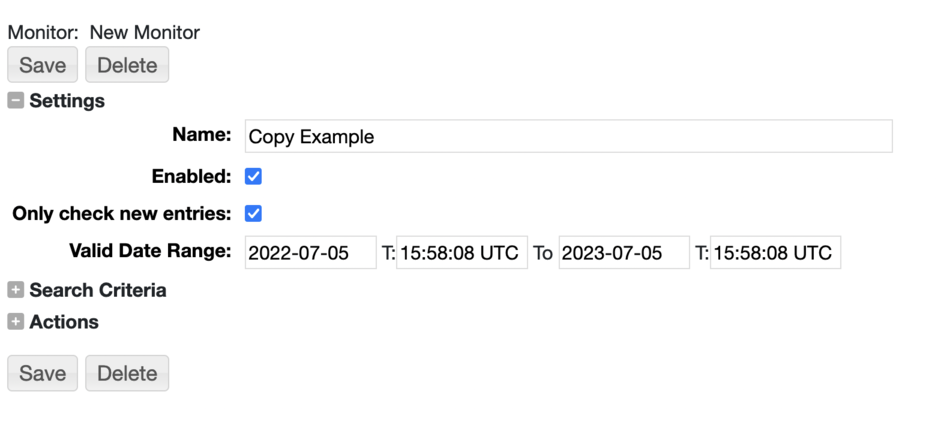
To create a monitor as a site administrator go to the Admin->Monitors page.
Select one of the monitor types to create. For example, here we have created a Copy Action.
This checks if a new entry meets the given search criteria and if so will copy that entry
into another folder.
Specify a name, whether the action is enabled and a valid date range for when the action can run.
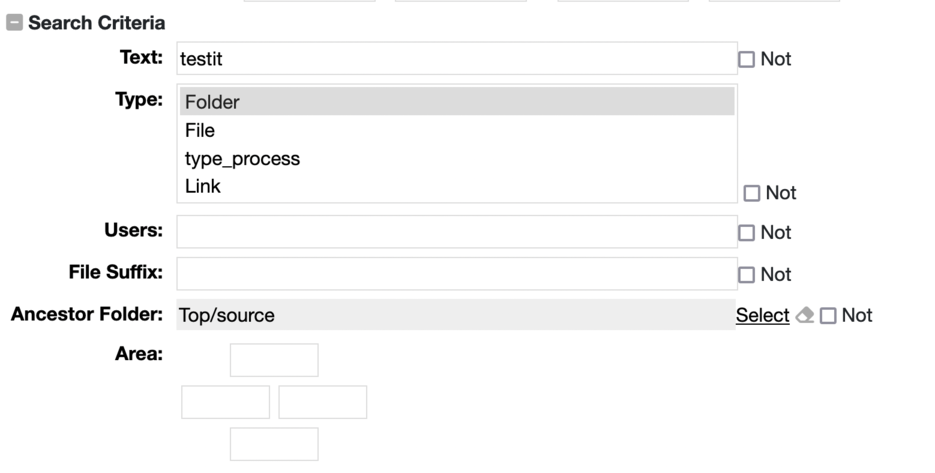
Next, specify the set of search criteria. For example, here we are only running this action
when a new entry is created with name that matches the pattern "testit", of type Folder that is under
the Top/source folder.
A number of monitor actions (e.g., Publish, Copy, GridSubset) create new entries under a specified folder entry.
A path template can also be specified. The path template supports creating any number of new sub-folders under the main
folder where the newly created entry will be added.
The path template takes the form:
sub_entry_name1/sub_entry_name2/...
Where each sub_entry_nameN is the name of a subentry that is created (of needed). Each sub_entry_name can contain a number of macros
that are are based on the newly created entry.
${filename}: the name of the file or URL
${fileextension}: the file extension
${name}: the name of the entry
${user}:the user id
The following are based on the entries from/to date and the create date
${create_date},${from_date},${to_date}:full formatted date
${create_day},${from_day},${to_day}:day of month
${create_week},${from_week},${to_week}:week of month
${create_weekofyear},${from_weekofyear},${to_weekofyear}:week of year
${create_month},${from_month},${to_month}:numeric month
${create_year},${from_year},${to_year}:year
${create_monthname},${from_monthname},${to_monthname}:month name
You can also specify the entry type of the subentry with the syntax:
sub_entry_name1:type=some_type/sub_entry_name2/...
For example, if you wanted to make use of RAMADDA's point collection types you could specify the path to be
${from_monthname} ${to_year}:type=type_point_collection
This would result in a Collection entry
with name derived from the month and year of the data of the newly created entry.
So, if your data file is from June 2022 then you would have, e.g.:
June 2022/data file1.csv
June 2022/data file2.csv
...
A nested example using the collection of collections entry type (example
here) would be:
Collection:type=type_point_collection_collection/${from_monthname} ${to_year}:type=type_point_collection
This would result in a Collection of Collections as the top-level entry called "Collection".
Under that entry is a Collection entry
with name derived from the month and year of the data of the newly created entry.
The Publish Monitor will automatically publish a new entry in a source RAMADDA into a destination RAMADDA.